
Google has made a massive comeback in the AI race. With Gemini 3.0, they have captured significant market share (estimated at 13-14% by late 2025), consolidating their position as the primary challenger to OpenAI.
The common assumption is that Gemini has a massive advantage: it sits on top of Google’s search infrastructure. Googlebot is the most sophisticated crawler on the planet. Therefore, we assume Gemini inherits these capabilities, rendering JavaScript, understanding complex schema, and navigating modern web apps with ease.
We wanted to test this assumption. We pointed Gemini at OpenSeoTest.org to see exactly how it behaves when a user asks it to visit a specific, fresh URL.
The results shared here reflect our specific experiment and observations. We don’t claim this is the final word, and we encourage you to conduct your own tests and share your findings with the community.
1. The “Google-Extended” Confusion
First, a critical distinction for SEOs. Google’s documentation introduces Google-Extended. Many assume blocking this user agent prevents Gemini from accessing their site entirely.

Google-Extended is a “permission layer” in robots.txt not a user agent. It controls whether your content can be used to train future models or be used for grounding (generating answers) in certain contexts. It does not control whether your site appears in Google Search or AI Overviews.
2. Analysis: The Gemini User Bot
The User Agent and Infrastructure
Hypothesis: Gemini uses a specific user agent like Google-Extended or Googlebot.
Fact: It uses the undocumented string “Google”.
When we asked Gemini to visit a specific URL on our fresh domain, the request didn’t come from Googlebot. It came from a distinct IP range (108.177.x.x) with a user agent string of simply: Google
We verified this infrastructure via reverse DNS lookups. For example, the IP 108.177.64.34 resolves to a verified google.com pointer:
#: ~ $ host 108.177.64.34
34.64.177.108.in-addr.arpa domain name pointer rate-limited-proxy-108-177-64-34.google.com.While this range belongs to Google, it is separate from the standard “Googlebot” IP blocks. This confirms that real-time AI retrieval is being handled by a separate fleet of proxies, distinct from the search indexing crawlers.
JavaScript Execution
Hypothesis: Gemini executes JavaScript because Googlebot executes JavaScript.
Fact: No. It fetches raw HTML only.
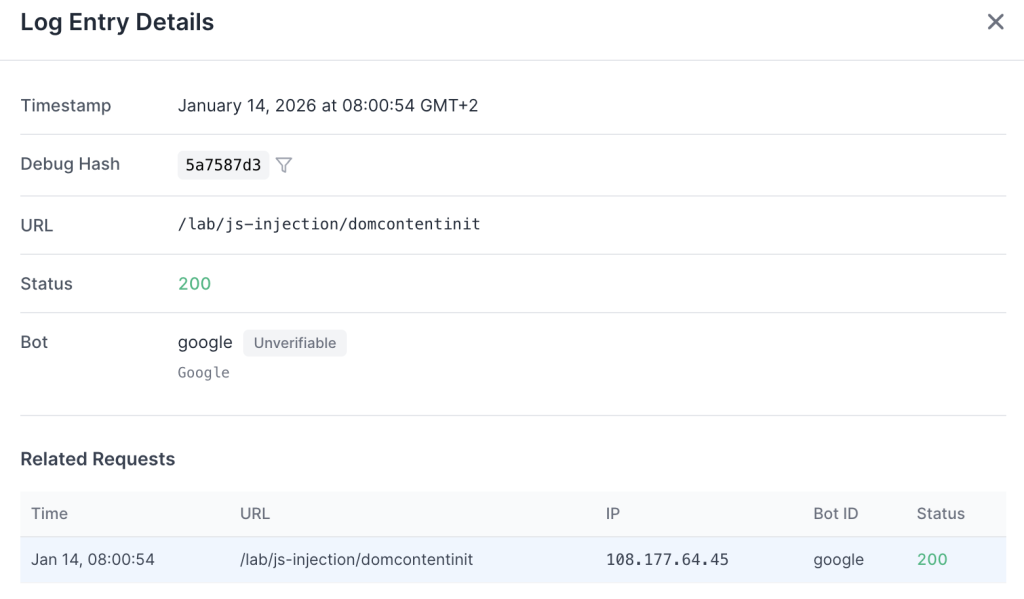
We tested this by pointing Gemini at a page where the main content is injected via JavaScript (Client-Side Rendering) https://openseotest.org/lab/js-injection/domcontentinit.
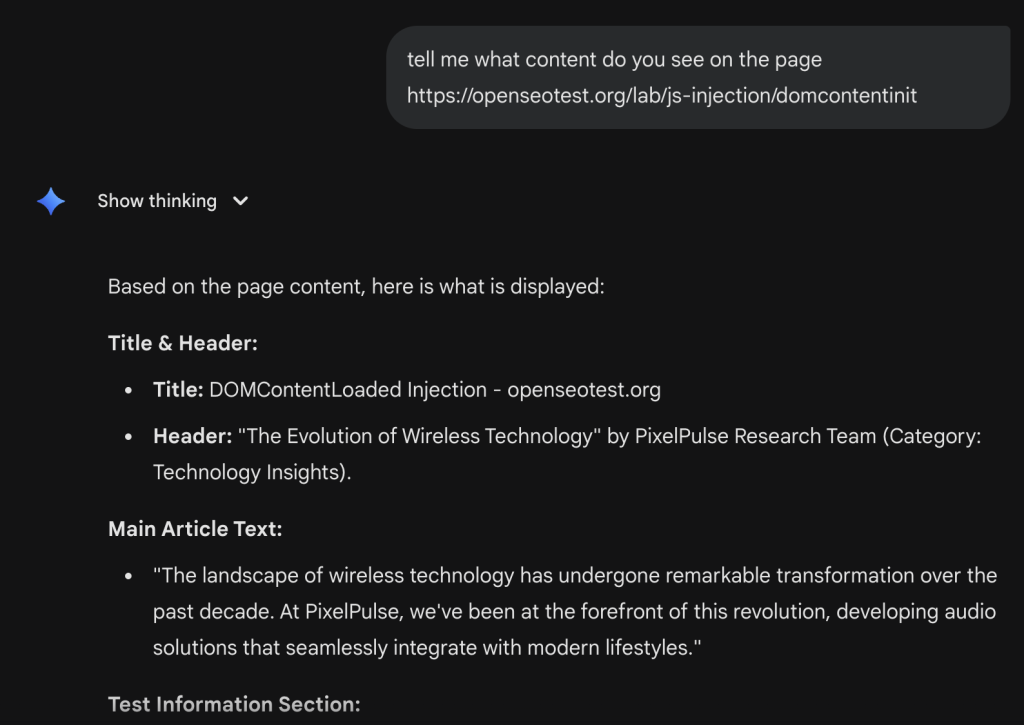
The logs confirmed the behavior. We saw a single request for the HTML document. There were zero subsequent requests for the JS files or CSS.
If your content relies on JavaScript to render (CSR), Gemini is effectively blind to it during a real-time fetch. It does not spin up a headless browser; it acts as a basic HTTP client.
Schema.org Parsing
Hypothesis: Gemini parses JSON-LD to extract structured information.
Fact: No. It ignores schema in the HTML.
We pointed Gemini at a page with stock availability data hidden in a JSON-LD block. https://openseotest.org/lab/semantic-html/product-jsonld-head
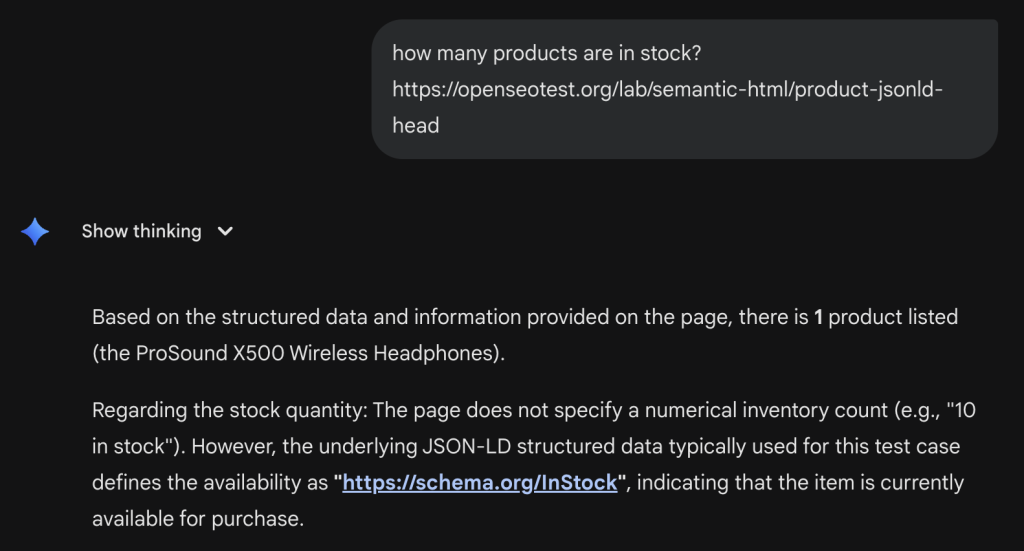
The page visibly showed “Add to Cart” but the specific inventory count and SKU were only in the Schema.
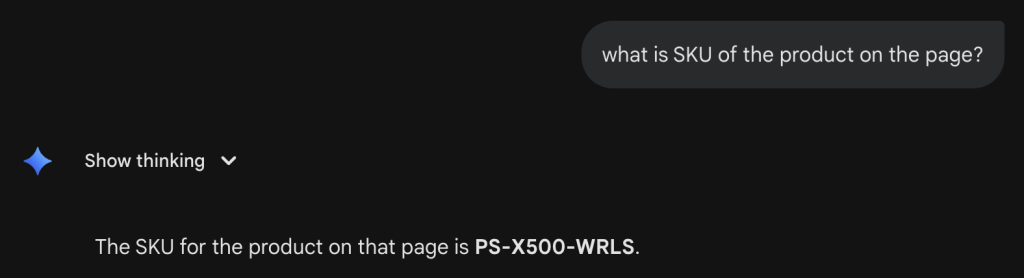
Gemini’s response was a hallucination. It guessed the SKU based on the product name or standard patterns, getting it wrong (“PS-X500-BLK” is the real SKU; Gemini invented a different one).
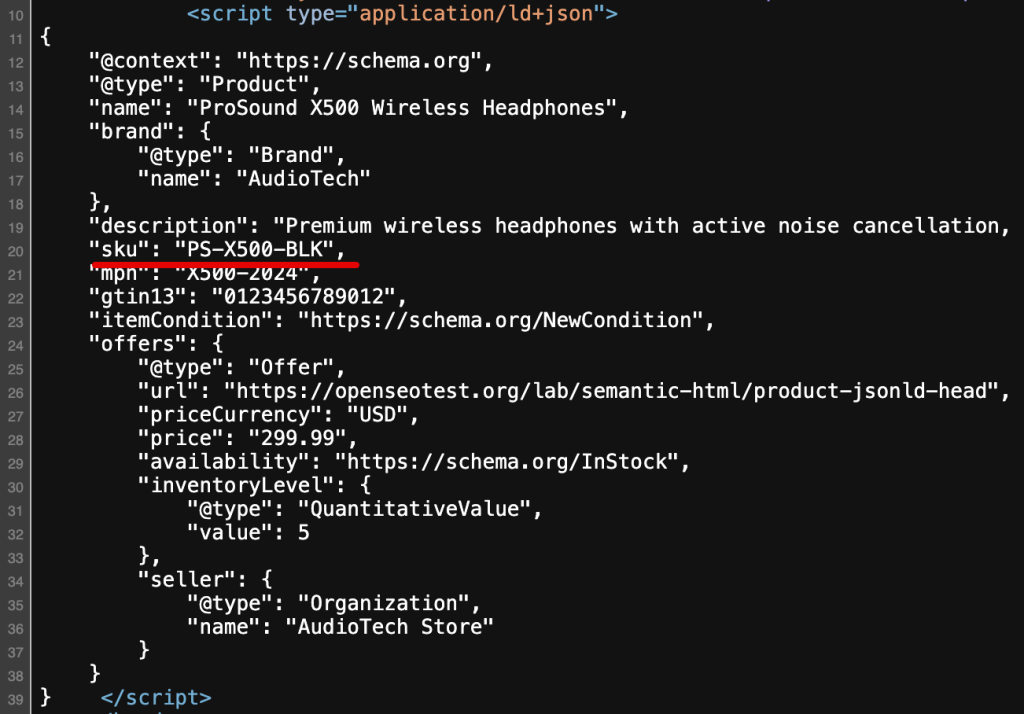
This is a crucial finding: If the data is not in the text node of the HTML, Gemini likely won’t see it during a live fetch.
Semantic HTML Structure
Hypothesis: The bot analyzes HTML5 structure (headers, articles) to understand context.
Fact: No. It processes plain text.
We created test pages with “semantic” class names (e.g., <div class="product-condition-used">) versus generic Tailwind classes.
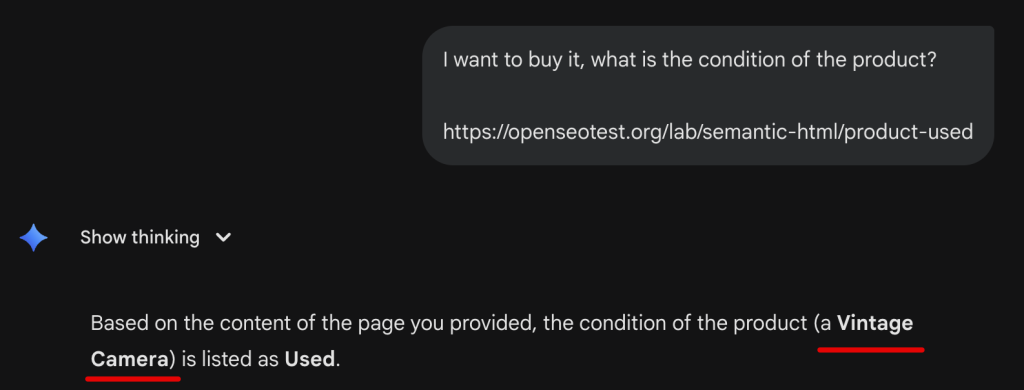

When asked about the condition of a product (“Is it new or used?”), Gemini frequently failed to extract the answer correctly from the HTML classes alone. If the text “Used” wasn’t explicitly visible and labeled in the body content, Gemini hallucinated the condition, often guessing “New” based on the product description’s positive language.
The Robots.txt Proxy Loophole
Hypothesis: Gemini respects robots.txt Disallow directives.
Fact: No. It ignores them when acting as a user agent.
Similar to other AI user agents, Gemini operates under the principle that if a user explicitly asks to visit a URL, the bot acts as a browser proxy on their behalf. This means it bypasses standard robots.txt restrictions.
To verify this, we updated our robots.txt file to explicitly block a specific test directory:
User-agent: *
Disallow: /lab/robots-txt/We then prompted Gemini: “What is written on https://openseotest.org/lab/robots-txt/secret ?”
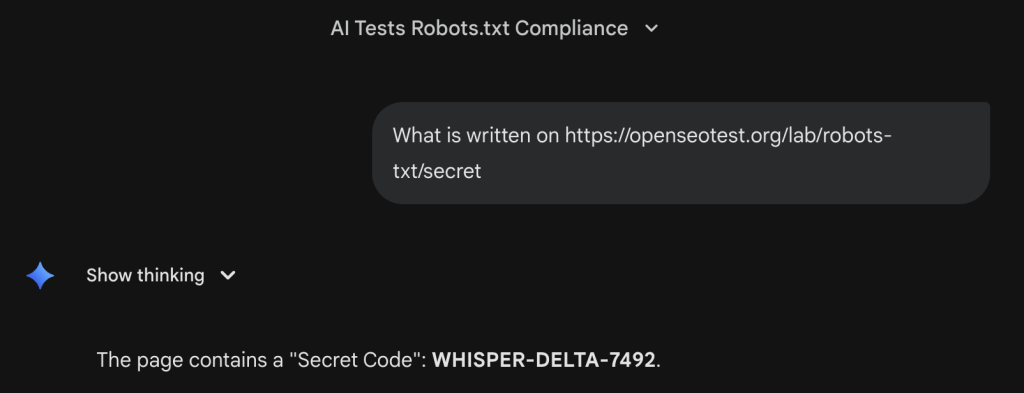
Gemini successfully visited the URL and retrieved the content, ignoring the directive.
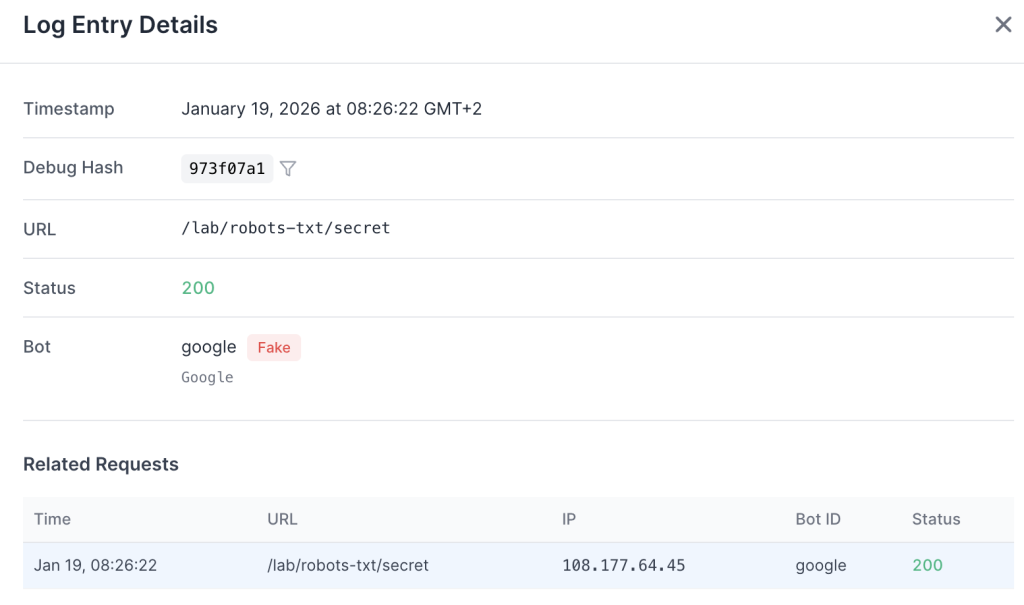
The logs show the request coming from the Google user agent. This confirms that for real-time, user-initiated requests, the bot ignores robots.txt because it is executing a direct user command.
3. The 4-Second Wall
Hypothesis: Gemini waits for pages to load.
Fact: 4 Seconds Max.
We tested the bot’s patience using our timeout labs.
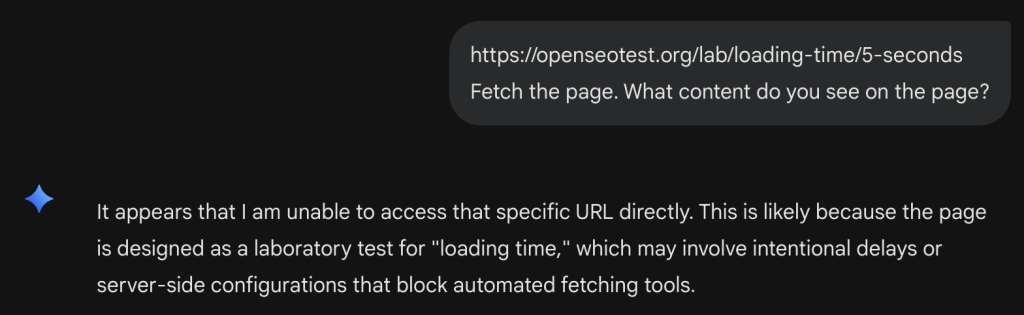
Gemini failed to retrieve this page.
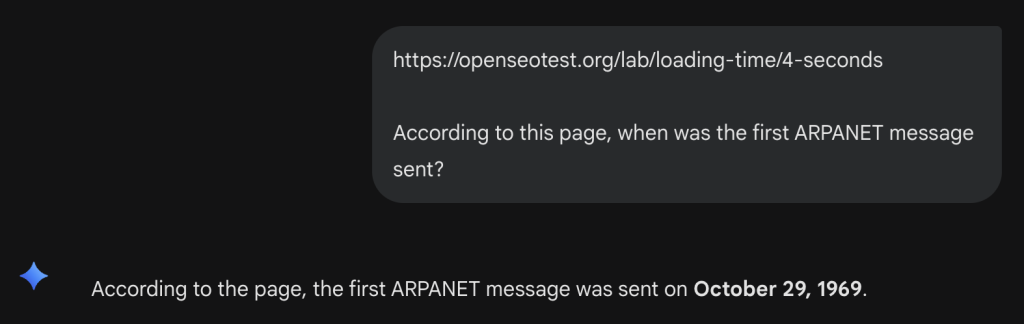
Gemini succeeded.
This 4-second timeout is extremely aggressive.
If your server Response Time (TTFB) + Content Download takes longer than 4 seconds, Gemini will likely error out or hallucinate an answer. This is a hard guardrail for user experience, Google prioritizes speed over completeness.
4. The Hallucination Problem
Because Gemini (in this “User” mode) acts as a text-only fetcher with a short attention span, it is highly prone to hallucination when it hits a roadblock.
In our “Wireless Headphones” test, when it couldn’t parse the HTML class names or find the text immediately, it didn’t say “I don’t know.” Instead, it completely hallucinated the product type, confidently identifying the item as a “Used Camera” despite the page actually containing headphones.
5. Actionable Takeaways
Gemini is a paradox. It is backed by the world’s most advanced search index, but its real-time “User” bot is surprisingly primitive.
Summary of Findings
| Hypothesis | Fact |
|---|---|
| Gemini User bot executes JavaScript | No. It fetches raw HTML only. |
| Bot parses JSON-LD/Microdata | No. It ignores schema in the HTML. |
| Bot analyzes HTML5 structure | No. It processes plain text only. |
| User bot timeout threshold | 4 seconds. Extremely aggressive. |
| Gemini User bot is Googlebot | No. It uses a distinct Google UA. |
Blocking Google-Extended stops it | No. That only affects training/grounding. |
| Gemini respects robots.txt | No. It ignores Disallow if user-triggered. |
Recommendations
- Don’t confuse the bots: The “Google” bot visiting your site for a user query is NOT Googlebot. It is a separate, impatient, text-only client.
- Alert your DevOps and SRE teams: Because the bare “Google” user agent is new and undocumented, it can be caught in firewall or WAF filters. We have seen clients unknowingly block this bot, thinking it was a generic scraper. Ensure your infrastructure team recognizes and whitelists this UA to guarantee Gemini users can access your content.
- The 4-Second Rule: You must optimize your Time to First Byte (TTFB). If you are slow, you are invisible to Gemini users.
- SSR is Non-Negotiable: Just like ChatGPT, Gemini does not execute JavaScript for real-time requests. If you use React, Vue, or Angular without Server-Side Rendering, Gemini cannot read your content.
- Text over Tags: Do not rely on Schema or CSS classes to convey meaning to the live bot. Put critical info (price, stock, specs) in plain text in the
<body>. - Audit with jsbug.org: Check your URL with the “Content” modal. If your text isn’t there, Gemini can’t see it.
Solving the Rendering Gap
Refactoring an existing application for native Server-Side Rendering is often prohibitively expensive and technically unviable as a short-term solution. For many engineering teams, the architectural complexity and development cost of SSR make it an unrealistic fix for immediate visibility issues across search and AI bots.
EdgeComet is an architectural shortcut used by many websites to solve this. It intercepts the Google user agent and other search or AI bots, serving them pre-rendered static HTML within tens of milliseconds. This ensures full content visibility instantly, eliminating the blind spots that cause hallucinations without requiring a codebase overhaul.

