
The State of JavaScript
I remember when a web page was just a document. You requested it, the server sent HTML, and the browser painted it. Simple, robust, and readable by anything with a network connection.
Today, we don’t build documents; we build applications.
This shift brought incredible user experiences, but it introduced a fundamental flaw: Fragility.
A classic HTML document with a syntax error usually still renders something. A JavaScript application with an uncaught exception? It’s the web equivalent of a Blue Screen of Death.
The screen goes white, the main thread halts, and for a crawler, the content simply ceases to exist.
Google has spent nearly two decades building its Web Rendering Service (WRS) to mitigate this, executing JavaScript to find the content hidden behind div id="root". But even Google has limits. And now, we have a new wave of visitors: AI bots.
The Reality: AI Bot Constraints
My analysis of recent crawler behavior reveals a clear technological divide. While Googlebot functions as a patient, sophisticated browser, the current generation of AI bots (including GPTBot, ClaudeBot, and PerplexityBot) is built on more primitive architectures designed for speed over rendering depth.
There are two reasons for this:
- Cost: Spinning up Headless Chrome to render a page uses orders of magnitude more CPU and RAM than simple text parsing.
- Latency: A heavy JS application can take 3-10 seconds to hydrate and fetch content. AI chat users demand answers in milliseconds. They simply don’t have time to wait for your
useEffecthooks to resolve.
The community has observed this, but observations aren’t data. We needed hard proof.
OpenSeoTest: A Reverse-Engineering Lab
In her presentation at Tech SEO Connect 2025, Jori Ford asked the critical question: “Okay, nice, but how can I test it?”
To answer this, we built OpenSeoTest.org (OST).
We designed OST as an open laboratory for the community. It eliminates the variables of complex production environments, offering a library of isolated test cases. These tests allow us to evaluate how bots handle specific scenarios:
- HTTP redirects (301, 302, 307, 308)
- Client-side hydration delays
- JavaScript error handling
- Network latency simulation
- AJAX Requests fetching data
The platform features a real-time Log Files Analyzer. By submitting a generated test URL to a bot (e.g., via a ChatGPT prompt or a Google Search Console inspection), researchers can immediately inspect the server logs. This reveals the exact sequence of resource requests, providing hard data on whether the bot executed the JavaScript or merely parsed the initial HTML.
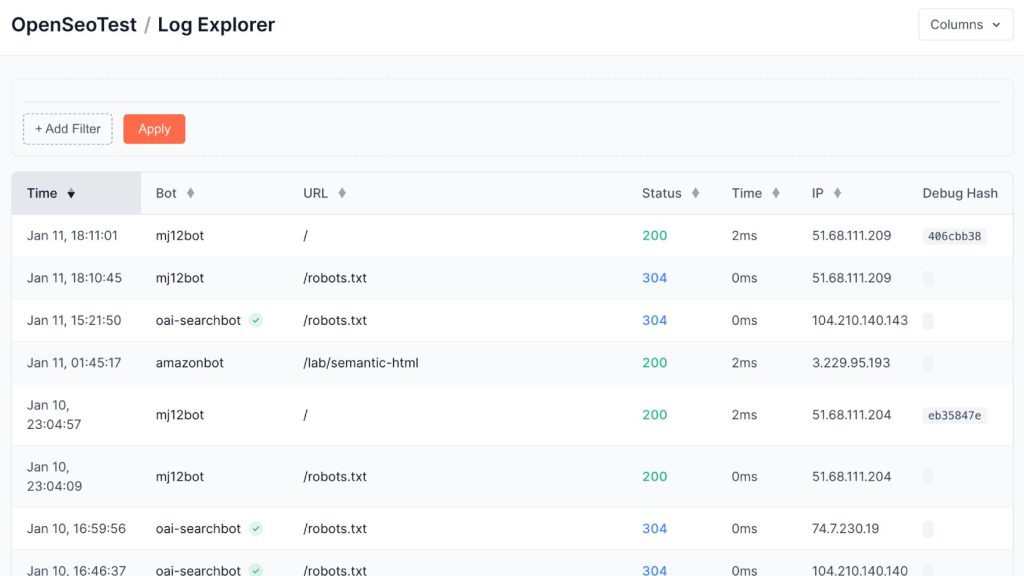
The Technology: The Debug Hash
To differentiate between simple HTML parsing and full JavaScript execution, standard analytics are insufficient. We need to verify if the client (bot) actually fetches sub-resources declared in the DOM.
We implemented a request-scoped tracking mechanism we call the Debug Hash.
For every request to an OST test page, the system generates a unique, 8-character hash. This identifier is dynamically injected into the paths of all critical resources (scripts, styles, XHR endpoints).
Instead of a static script tag:
<script src="/js/app.js"></script>OST generates a unique path for that specific session:
<script src="/dist/a7f3b2c1/js/app.js"></script>
<link rel="stylesheet" href="/dist/a7f3b2c1/css/site.css">This architecture provides deterministic verification in our access logs:
- Initial Fetch: The bot requests the test URL
/lab/test/a7f3b2c1. - Execution Check: We query the logs for the corresponding resource request
/dist/a7f3b2c1/js/app.js.
– Confirmed: he bot parsed the DOM and executed the resource fetch.
– Negative: The bot only consumed the initial HTML payload.
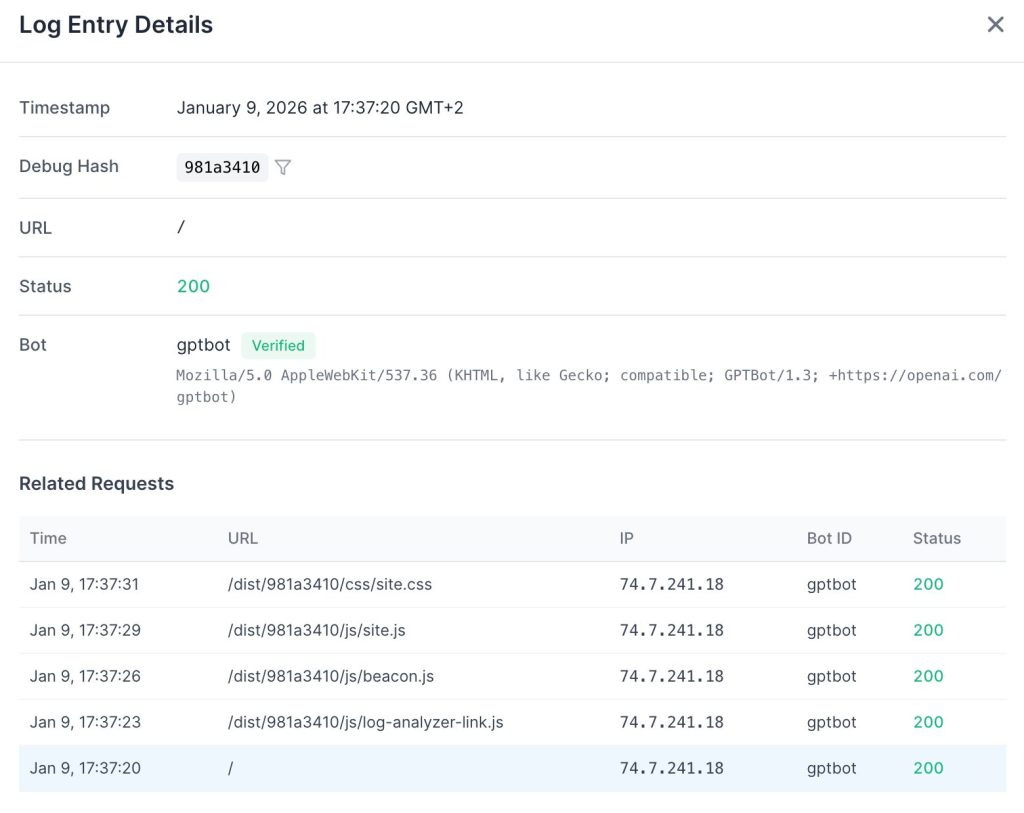
This allows us to isolate traffic by hash and determine, with binary certainty, whether a specific bot instance is rendering the page or merely scraping the source.
First Field Results
We have already put this architecture to the test against OpenAI’s fleet. The results confirm our suspicions: the ChatGPT User bot behaves strictly as a text-fetcher, ignoring JavaScript and timing out after just 5 seconds. For the full breakdown of how GPTBot, OAI-SearchBot, and ChatGPT User behave in the wild, read our detailed OpenAI Bots Research.
How to Participate
We built the architecture to be intentionally flat and hackable. No complex build chains, no heavy frameworks. It’s pure old-school PHP.
For Developers (and AI agents)
The project structure is designed for rapid contribution. If you use tools like Claude Code or Gemini, you can simply point them at the repository. They can help you scaffold new tests by adding definitions to config/tests.php and creating the corresponding templates in src/Templates/pages/.
For the SEO Community
You don’t need to be a developer to contribute. If you have a hypothesis – “Does PerplexityBot wait for a 5-second AJAX delay?” – just open an issue on GitHub. Describe the scenario you want to test, and our team will implement it for you and add it to the public library.
Conclusion
Technical SEO shouldn’t be a guessing game based on vague documentation. By building a community-driven library of tests with open, verifiable results, we can move away from speculation and toward evidence-based strategies.
OpenSeoTest is our attempt to bring engineering rigor to SEO research. It’s open-source, it’s live, and it’s waiting for your input.

