When you optimize a website for search and AI visibility, you think about content quality, page speed, structured data, and Core Web Vitals. You probably don’t think about where the bots crawling your pages are physically located. Most SEO professionals I know have never checked.
That changes once you realize that all autonomous AI crawlers operate from a single country. If your site uses geo-based traffic blocking, you might be locking them out without knowing it. If your server is far from their data centers, crawl latency eats into their rendering budget.
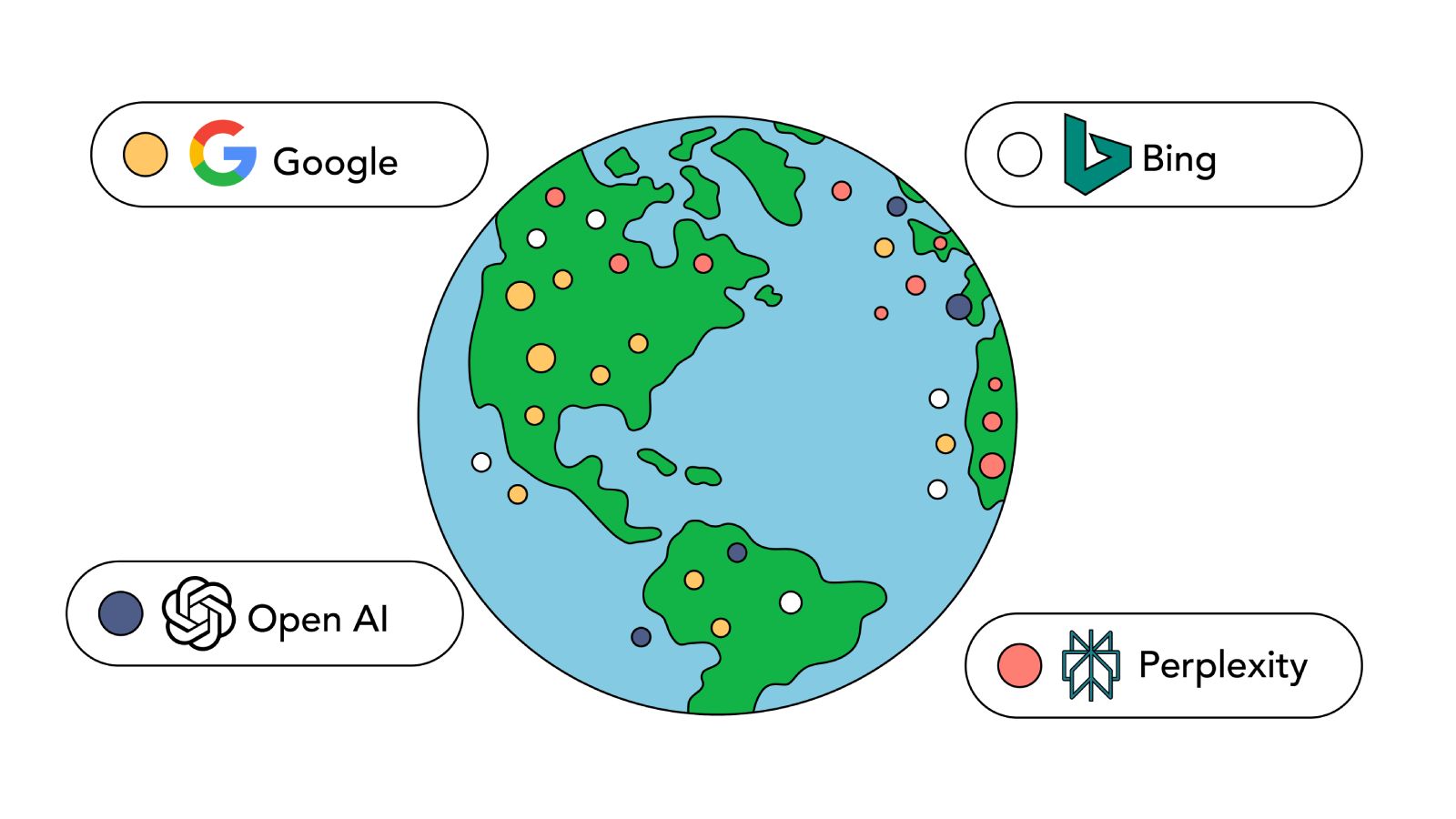
We analyzed every publicly available bot IP range from Google, Bing, OpenAI, and Perplexity. That gave us 484 subnets covering approximately 19,116 IP addresses across 7 distinct crawler identities. We mapped each subnet to its geographic location to answer a straightforward question: where do these bots actually operate?
One notable absence: we wanted to include Anthropic’s ClaudeBot in this analysis, but Anthropic does not publish its crawler IP ranges. ClaudeBot is excluded for that reason alone.
How We Geolocated These IPs
GeoIP lookup sounds simple: feed an IP address into a database, get a country and city. In practice, it’s not that straightforward. Different GeoIP databases produce different results for the same address, and the discrepancies are not small.
I started with ipinfo.io, one of the most commonly recommended services. When I ran Googlebot’s well-known 66.249.x.x subnets through it, ipinfo.io placed them in Belgium. That immediately looked wrong. These are among the oldest and most documented Googlebot ranges, and they have been associated with US-based Google infrastructure for years.
I cross-checked against several other databases. MaxMind’s correctly placed those same subnets in the United States. So did several other providers. The Belgium result from ipinfo.io appeared to be an outlier.
We chose MaxMind as the primary data source for this analysis. GeoIP data reflects IP registration records and network routing, not the physical rack location of a server. But for our purpose, identifying which country and city a crawler operates from, it is reliable enough.
If you run your own IP analysis, be aware: your choice of GeoIP database will affect your results. I recommend cross-checking critical findings against at least two sources.
The Overview: 7 Bots, 484 Subnets
Here is the full picture. This table summarizes every crawler we analyzed.
| Bot | Type | Subnets | Est. IPs | Countries | Cloud Provider |
|---|---|---|---|---|---|
| Googlebot | Search engine | 165 | ~4,928 | 22 | Google Cloud |
| Bingbot | Search engine | 28 | ~4,736 | 14 | Microsoft Azure |
| ChatGPT-user | AI browser | 224 | ~3,584 | 15 | Microsoft Azure |
| GPTBot | AI crawler | 20 | ~3,344 | 1 (US only) | Microsoft Azure |
| SearchBot | AI search | 35 | ~2,496 | 1 (US only) | Microsoft Azure |
| PerplexityBot | AI crawler | 8 | ~14 | 1 (US only) | AWS |
| Perplexity-user | AI browser | 4 | ~14 | 1 (US only) | AWS |
| Total | 484 | ~19,116 |
Look at the “Countries” column. That single column tells the entire story. Googlebot: 22 countries. Bingbot: 14. ChatGPT-user: 15. Every autonomous AI crawler: 1.
Traditional Search Crawlers: Global by Design
Googlebot and Bingbot operate fundamentally different infrastructure from the AI crawlers. Both have invested in worldwide crawl networks.
Googlebot runs 165 subnets across 22 countries. Its legacy IP ranges (66.249.x.x and 192.178.x.x) are registered to the US without specific city data. Its newer ranges (34.x.x.x) map to Google Cloud regions worldwide: Montreal, Sao Paulo, Santiago, Frankfurt, London, Paris, Warsaw, Milan, Madrid, Zurich, Tel Aviv, Mumbai, Singapore, Tokyo, Seoul, Jakarta, Taipei, Hong Kong, Sydney, and more. Google strategically placed crawl nodes in nearly every major cloud region. The international subnets are more recent additions, meaning Google has been actively expanding Googlebot’s geographic footprint.
Bingbot covers 14 countries with just 28 subnets, packing significant IP capacity into large US blocks (/22 through /24). Its international points of presence use smaller /28 blocks. Bingbot is the only crawler in this dataset with a presence in China (Beijing) and the UAE (Dubai), regions no other crawler covers.
| Bot | US Subnets | Int’l Subnets | US % | Int’l Countries |
|---|---|---|---|---|
| Googlebot | 143 | 22 | 87% | 21 |
| Bingbot | 15 | 13 | 54% | 13 |
The key difference: both maintain international crawl nodes, giving them the ability to reach your site from a closer location. In practice, server log analysis shows Googlebot still sends the majority of requests from its legacy US-based 66.249.x.x ranges. The international subnets exist, but they are not the primary source of crawl traffic.
AI Crawlers: The Geographic Blind Spot
Every autonomous AI crawler in our dataset operates exclusively from US data centers.
GPTBot (OpenAI’s training data crawler) uses 20 subnets across just 3 US cities: Phoenix, AZ; Atlanta, GA; and Des Moines, IA. Despite having only 20 subnets, it commands ~3,344 IPs through large /24 and /25 blocks. It has zero international presence. Every website outside the United States that GPTBot crawls is accessed across an ocean.
SearchBot (OpenAI’s ChatGPT Search crawler) operates from ~5 US cities with 35 subnets. It shares overlapping IP ranges with GPTBot, confirming they run on the same Azure infrastructure. SearchBot also has zero international presence.
PerplexityBot and Perplexity-user combined have 12 subnets and approximately 28 IPs total. All of them are in Ashburn, Virginia (AWS us-east-1). Perplexity’s entire crawler fleet fits in fewer IP addresses than a single Googlebot /27 subnet. This is the smallest crawler infrastructure in the dataset by a wide margin. However, Perplexity has been accused of using third-party crawling services that do not identify as PerplexityBot in their user agent. If true, the actual volume of Perplexity’s crawl traffic is significantly larger than these 28 IPs suggest – it simply is not visible under their published ranges.
ChatGPT-user is the notable exception. With 224 subnets across 15 countries and 48% of its subnets outside the US, its infrastructure is distributed globally. This makes sense: ChatGPT-user is a RAG bot that fetches content on behalf of end users in real time. It has nodes in Dublin, London, Frankfurt, Warsaw, Milan, Madrid, Tokyo, Seoul, Singapore, Sydney, Sao Paulo, and more.
Estimated IP Addresses by Crawler
Based on CIDR block sizes from publicly available IP range lists
IP counts are estimates based on CIDR block sizes and represent address space, not active crawlers.
The divide is clear. Traditional search engines distribute globally. Autonomous AI crawlers do not.
Why This Matters: Latency, Rendering, and Visibility
Geographic distance between a bot and your server has direct, measurable consequences.
Crawl Latency
A bot in Phoenix, AZ crawling a website hosted in Frankfurt, Germany incurs ~130-150ms of network round-trip time before any server processing begins. For a bot in Ashburn hitting a server in Tokyo, that’s ~170-200ms. These numbers are pure physics: the speed of light through fiber.
Bots allocate a finite time window for crawling each site. Higher latency per request means fewer pages crawled in that window. A website in Asia-Pacific crawled by US-only GPTBot gets fewer pages processed than an equivalent US-hosted site, purely because of distance.
JavaScript Content Delivery
Our research on OpenAI and Gemini bots confirms that current AI crawlers do not render JavaScript at all. They fetch raw HTML and stop. If your content depends on client-side rendering, it is invisible to these bots regardless of where they operate from.
For sites that do serve complete HTML, the geographic problem still applies. ChatGPT-User times out at 5 seconds. Gemini’s user bot times out at 4 seconds. A server in Asia-Pacific responding to a US-based bot starts with 150-200ms of network latency before any server processing begins. On a slow origin, that timeout window closes fast.
Actionable Takeaways
Check your geo-blocking rules. If your site uses country-based access restrictions (common for medical sites regulated by US state law, or US sites that block European traffic to avoid GDPR obligations), verify that US IP ranges are not blocked. GPTBot, SearchBot, and PerplexityBot operate exclusively from US data centers. Cross-reference your firewall and CDN rules against the official published IP lists from Google, Bing, OpenAI, and Perplexity. Keep in mind that DevOps and SRE teams often update firewall and CDN rules independently, without notifying the SEO or marketing team. A well-intentioned security change can silently block crawler traffic. Establish clear communication channels with these teams so they understand which IP ranges must stay accessible. A sudden block can cause significant drops in both search traffic and AI visibility.
Geolocate the bots hitting your server. Check your access logs for AI bot user agents and map their IP addresses. If your server is in Europe or Asia-Pacific and you see GPTBot or PerplexityBot requests coming exclusively from US IPs, the network latency tax is a given – you just can’t measure it from your side. Factor this into your performance budget.
Pre-render and pre-cache for AI bots. AI crawlers do not execute JavaScript. If your site relies on client-side rendering, the content is invisible to them regardless of geography. Pre-rendering solves the visibility problem, and pre-caching ensures the response is served as fast as possible – critical when bots impose 4-5 second hard timeouts and every millisecond of network latency counts. Tools like EdgeComet handle both at the edge, serving bots fully rendered HTML without changes to your frontend code.
Verify your AI search visibility regularly. Pick a set of key pages and periodically ask ChatGPT or Perplexity to fetch specific information from those URLs. If the bot cannot retrieve the content or returns incorrect data, investigate. The cause may be a geo-block, a timeout from geographic distance, or JavaScript content that the bot never sees. This is a simple, repeatable check that catches visibility problems before they affect your traffic.