Your website looks perfect in Chrome. The animations are smooth, the content loads beautifully, and everything works exactly as designed. But what does Googlebot actually see? Or, more importantly nowadays, what does ChatGPT, Claude, or Perplexity actually see?
For most JavaScript-heavy websites, crawlers often see a skeleton, a shell of placeholder text and empty containers. We’ve spent years debugging this exact problem.
We built jsbug.org specifically to expose this problem and help users analyze their websites for free.
The JavaScript Rendering Gap
Modern web development has embraced client-side rendering. When a user visits your site, the server sends a tiny, almost empty HTML shell. Then, a massive bundle of JavaScript downloads, executes, fetches data from an API, and finally constructs the DOM (Document Object Model).
The problem is that browsers and crawlers operate under completely different constraints.
When a browser visits your page, it has time, memory, and CPU cycles to use. It can wait for API calls, execute scripts, and render a complex DOM. But crawlers need to process billions of pages. They can’t afford to spin up a full browser environment for every URL they encounter.
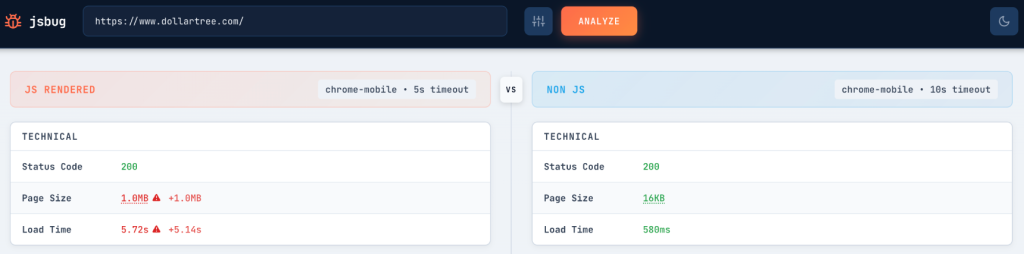
Rendering a JavaScript-heavy page in a headless browser can take 30 seconds or more, compared to less than a second for fetching raw HTML. A browser session uses roughly 100x more RAM and 10x more CPU than a simple HTTP fetch for the same page.
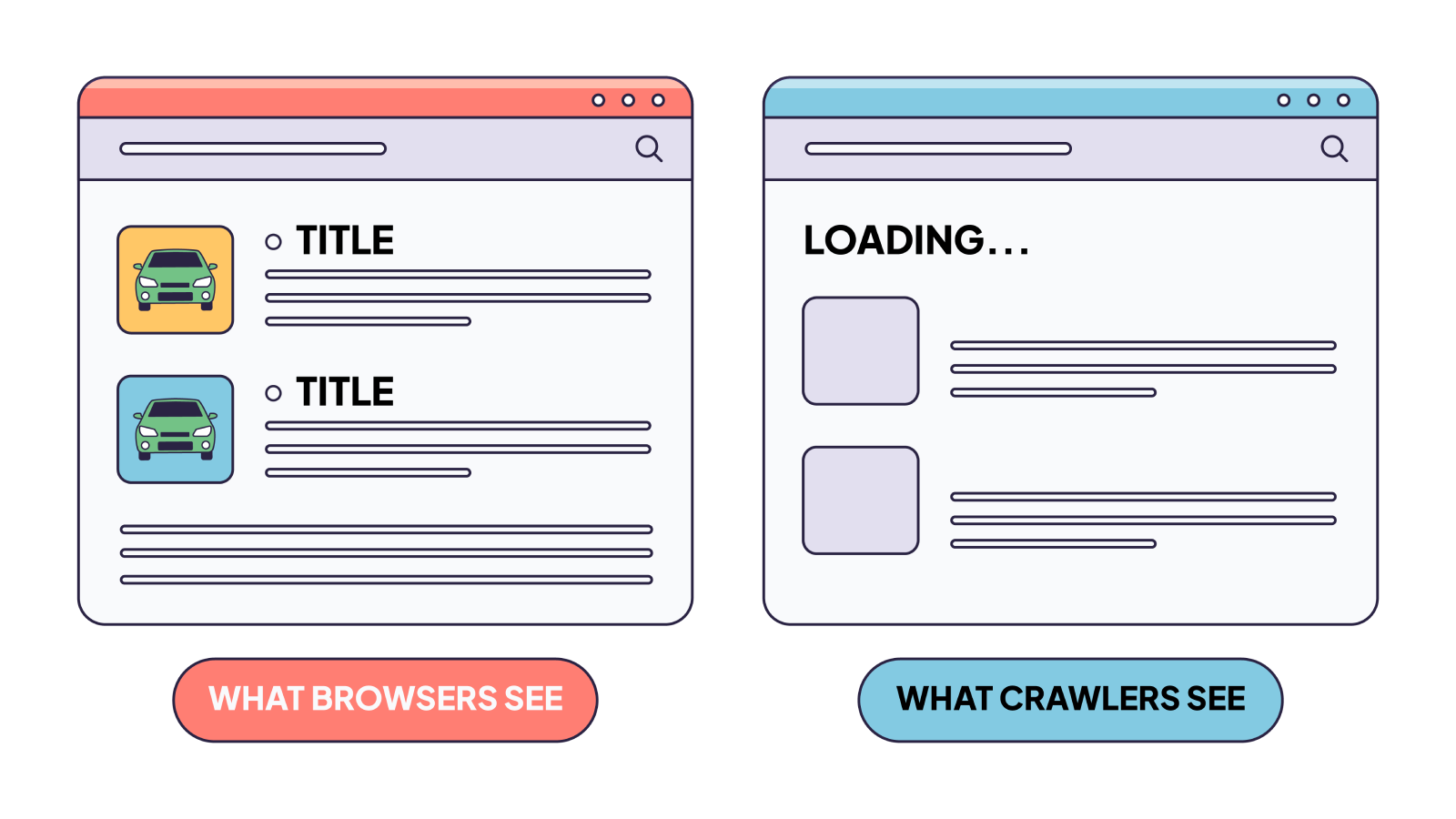
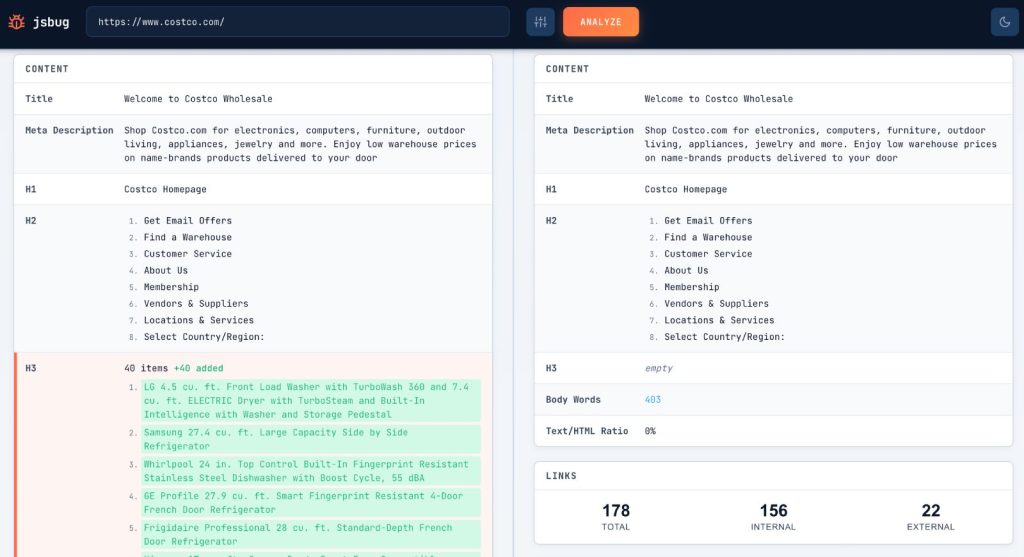
This isn’t a theoretical concern. If your homepage shows 2,000 words of content in Chrome but only 50 words in the raw HTML source, you have a rendering gap. And that gap determines what crawlers can actually index.
Who’s Affected: The Three Types of Crawlers
Not all crawlers behave the same way. Understanding their differences is critical to diagnosing visibility problems.
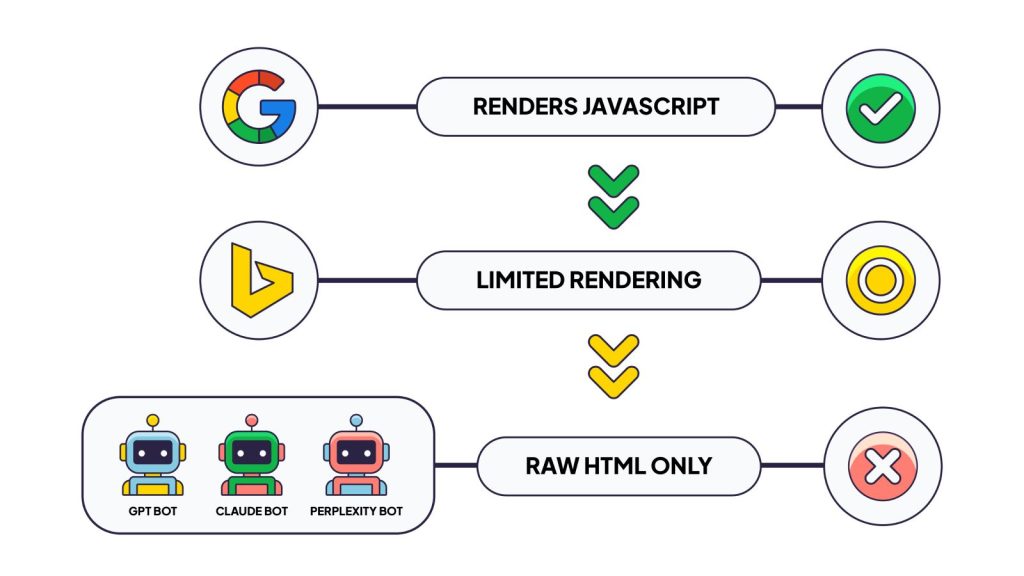
Google: Renders JavaScript, But With Constraints
Google operates the most sophisticated web crawling infrastructure. Their Web Rendering Service (WRS) uses an evergreen headless Chromium to execute JavaScript and build the full DOM.
But Google’s rendering isn’t free, and the modern story is less about delayed indexing than about whether Google decides to render your page in the first place. The old “two-wave” model, where Google would index the raw HTML now and render later, has largely collapsed. Rendering today usually happens within minutes of crawl. What still varies is whether the page clears Google’s prerequisites for rendering at all.
Before sending a page to the Web Rendering Service, Google reads the raw HTML and checks a few gates: the response must be 200 OK, the page must not carry a noindex directive, and the canonical must point at a renderable URL. If any gate fails, Google doesn’t spend rendering resources on the page, and anything your JavaScript would have added never gets seen.
Still, Google operates within resource limits. Pages with total resource payloads exceeding 2MB approach a danger zone for rendering reliability. Content that takes more than 3-5 seconds to appear after initial page load risks being missed entirely.
The transition to mobile-first indexing (completed in July 2024) adds another layer: all indexing now relies on what a mobile user agent sees. Content inaccessible on mobile becomes permanently unindexable.
Other Search Engines: Limited Rendering Capabilities
Bing and smaller search engines have invested less in JavaScript rendering infrastructure. They rely more heavily on raw HTML content. If your critical content requires JavaScript execution to appear, these engines may miss it entirely or index an incomplete version.
AI Bots: Zero JavaScript Execution
Here’s where things get serious for anyone thinking about AI-powered search.
OpenAI’s GPTBot, Anthropic’s ClaudeBot, and Perplexity’s PerplexityBot all operate under a zero-JS execution policy. They fetch your page’s raw HTML and process only that. No script execution, no API calls, no dynamic content loading.
This isn’t a temporary limitation, it’s a deliberate architectural choice. These crawlers need to ingest massive volumes of content quickly and cheaply. Rendering JavaScript at scale would require infrastructure investments comparable to what Google has built over two decades.
The traffic from these bots is substantial. GPTBot and ClaudeBot combined generate roughly 28% of the request volume that Googlebot produces. As AI-powered search grows through ChatGPT, Claude, Perplexity, and others, content that’s invisible to these crawlers becomes invisible in AI-generated answers. Understanding how these bots interact with your website often requires a log file analyzer that can reveal which pages they visit and how frequently they return.
If your content only exists after JavaScript execution, it won’t appear in AI search results. It won’t train future models. It won’t be cited when users ask questions that your content could answer.
What Can Go Wrong: Five Critical Areas
The rendering gap doesn’t affect everything equally. Certain elements are particularly vulnerable.
Core Content Not Visible
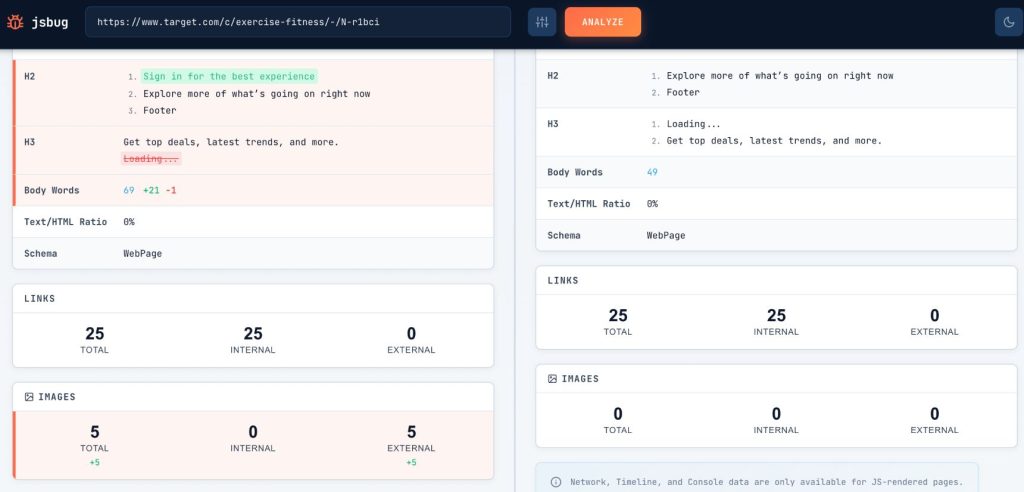
This is the most obvious failure. Your product descriptions, article text, or service information are available only after JavaScript loads data from an API. Crawlers see empty containers or “Loading…” placeholders. The actual content that should be indexed simply doesn’t exist in what they receive.
Metadata Missing
Title tags and meta descriptions are critical for both rankings and click-through rates. If your framework injects these via JavaScript, common in single-page applications, crawlers may index your page with a generic or missing title.
Google’s system defaults to whatever metadata exists in the raw HTML if rendering fails. A page indexed with “Loading…” as its title won’t attract many clicks.
Links Not Crawlable
JavaScript-based navigation can break link discovery entirely. If your internal links rely on click handlers rather than proper <a href=""> tags in the HTML, crawlers can’t follow them. This affects how search engines discover new pages and understand your site’s structure.
The crawl budget implications are significant. If Googlebot can’t discover pages through normal link-following, those pages may never get indexed at all.
Structured Data Invisible
JSON-LD structured data tells search engines what your content means, product prices, article authors, FAQ answers, recipes, and events. If this markup is injected via JavaScript, it may not be present when crawlers process your page.
Missing structured data means missing rich snippets. Your product pages won’t show star ratings in search results. Your FAQ content won’t appear in featured snippets. The competitive disadvantage compounds over time.
Social Sharing: The Forgotten Problem
There’s another category of crawlers that often reveals rendering problems first: social media bots.
When someone shares a link on Twitter/X, LinkedIn, Slack, or Discord, those platforms fetch your page to generate a preview. Every single one of these operates without JavaScript execution. They grab the raw HTML, extract Open Graph tags, and display whatever they find.
If your og:title, og:description, and og:image tags are injected via JavaScript, these platforms see nothing. The shared link appears blank or displays generic fallback text. It’s immediately visible when you share your own content and wonder why the preview looks broken.
This makes social sharing failures an excellent canary for broader rendering problems. If Twitterbot can’t see your metadata, neither can GPTBot, ClaudeBot, or PerplexityBot. The same architectural issue affects all of them.
Since many rendering issues don’t produce obvious user-facing errors, they can persist for weeks before anyone notices. SEO alerts can help teams identify visibility problems sooner and respond before they affect rankings or organic traffic.
Real-World Impact
We’ve seen the consequences of the rendering gap extend far beyond technical curiosity.
Pages don’t rank despite quality content. You’ve invested in excellent articles, product descriptions, or documentation. But if that content exists only after JavaScript execution, search engines may index a thin version of the page. Low word count, missing headings, and absent keywords, all the signals that help pages rank, are simply not there.
Rich snippets disappear. Without structured data in the indexed version of your page, you lose the visual enhancements that drive clicks: star ratings, price ranges, FAQ accordions, recipe details.
AI assistants can’t answer questions about your offerings. When someone asks Claude or ChatGPT about your product category, your content isn’t in the training data or retrieval corpus. You’re invisible to an entire emerging search channel.
Crawl budget gets wasted. Heavy pages that fail to render properly consume Googlebot’s resources without providing indexable content. This is particularly damaging for large sites where crawl budget allocation already matters.
Social sharing underperforms. Every link shared on LinkedIn, Twitter, or Slack with a broken preview is a missed opportunity. Colleagues share your content internally, but the preview shows nothing compelling. The click never happens.
How to Check Your Site
Diagnosing these issues doesn’t have to be complicated. We’ve put together a comprehensive guide on the most common symptoms of rendering failures.
Read 8 JavaScript Red Flags That Harm Your SEO (And How to Find Them) to learn how to audit your site in just a few minutes.
jsbug.org is free and open source, our contribution to the community. The same philosophy drives EdgeComet, the rendering infrastructure we’ve built to solve these issues at scale.